使用mitmproxy自动化采集微信公众号数据
最近因为工作需求,需要采集一批公众号的发文数据。
遇到需求,先谷歌。
在谷歌搜了一下公众号的采集
然后在GitHub上找到了一个库,微信公众号文章爬虫,看了一下Readme,有两种思路:
- 一种是从微信公众号平台获取,这种最简单只需要有一个公众号就可以获取数据,
- 另一种是写参数然后requests请求获取数据,这种会遇到参数过期的情况
本来是想选择第一种方式的,但是公司不提供公众号,那么只能用第二种了。
然后在吾爱上找到了一篇Fiddler抓取PC版微信公众号所有稳增长数据的分析给了我一点点的思路。
这里需要准备一个旧版微信,我这里用的是2.9.5。打开微信公众号的话,会有历史文章可以查看,之后再循环获取数据就行了。
——————————————————————————————————————————————
https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz={公众号编号}&f=json&offset={offset}&count=10&is_ok=1&scene=124&uin={访问者编号}&key={key}&pass_ticket={pass_ticket}&wxtoken=&appmsg_token={appmsg_token}&x5=0&f=json
从上面分析能得出获取文章列表的url地址,其中
标红的每次访问时获取的参数,半小时有效
标蓝的为固定,同一公众号固定,同一访问者固定
标粉的为页面数,从0开始,一次10篇;第一页为0,第二页为10,第三页为20,类推说明:offset里的一篇指的是一次推送,一次推送里可以是一篇文章也可以是多篇文章。
在获取到了一次的链接后,提取出{公众号编号}、{访问者编号}、{key}、{pass_ticket}、{appmsg_token},然后只需要在链接里修改{offset},就能达到读取所有的文章。
还是以 吾爱破解论坛 为例,通过修改offset,把最开始发布的文件找出来。
经过多次测试,确定893为最开始的一篇文章,894就没有文章了
这里引用这篇文章最重要的部分。
也就是说,我们想要持续采集的话,一个是需要公众号的id,然后就是用户的id,再就是Key,pass_ticket以及appmsg_token。
公众号的id和用户id只需抓包对应的公众号,而另外三个有时效的参数则不行。
- 一种方法是手动
- 另一种是自动
因为懒,所以肯定是要自动的。
我的思路就是使用自动化操作工具,每30分钟访问一边公众号,获取参数存入redis。这样在循环请求的时候就可以无缝衔接了。
自动化操作的工具好说,比如说按键精灵,亦或者python的pyautogui等等,都可以自动化操作微信进行点击
但是怎么拦截请求呢?
- 一种是fiddler等抓包软件,然后利用自动化操作工具复制
- 另一种就是使用mitmproxy
这里选择的是mitmproxy,设置代理然后所有的链接都会经过这个代理,然后就可以获取数据了。
安装的话推荐在一个新的python环境中安装
1 | conda create --name=mitmproxyWork python=3.9 |
配置的话,随便搜一下就能搜出来,这里附一份安装的教程。在配置好后启动mitmproxy
直接在cmd中输入
1 | mitmweb |
会打开一个可视化的web界面,然后重点就来了:
打开电脑的网络和Internet中的代理,设置地址为127.0.0.1然后端口为8080
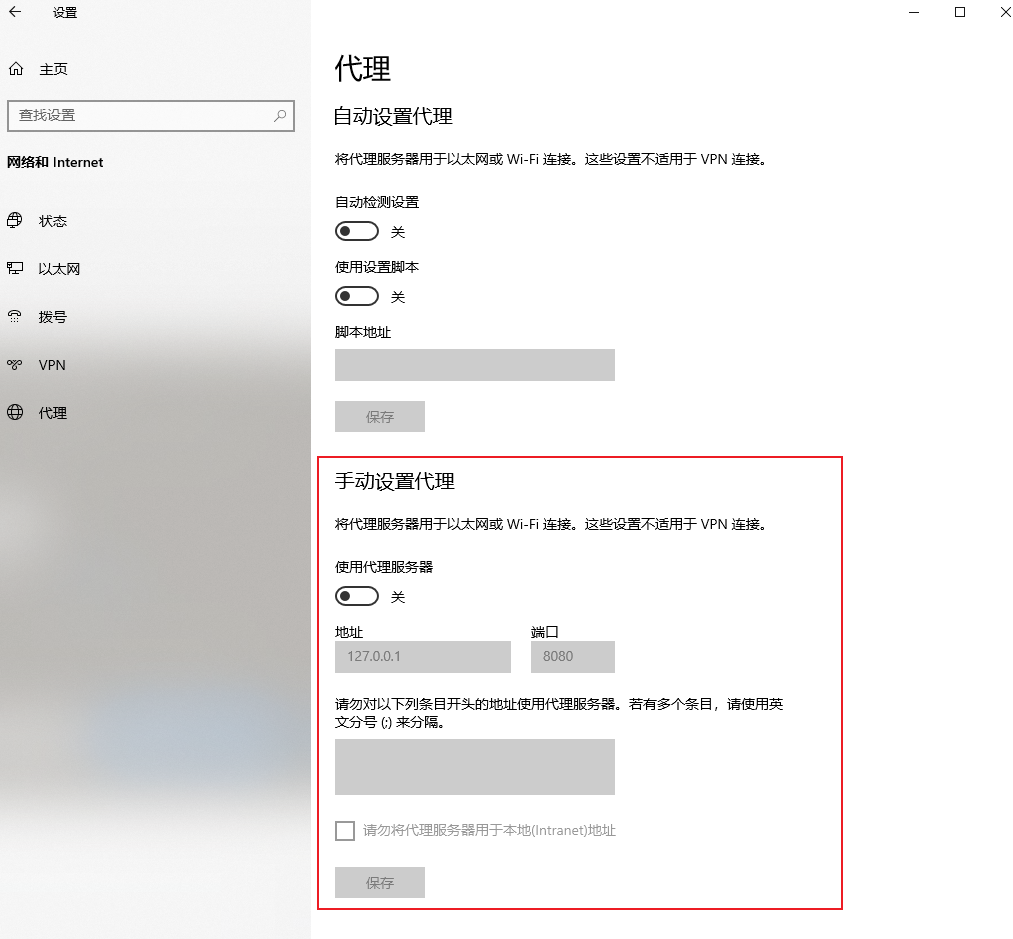
之后用微信访问公众号即可加载数据
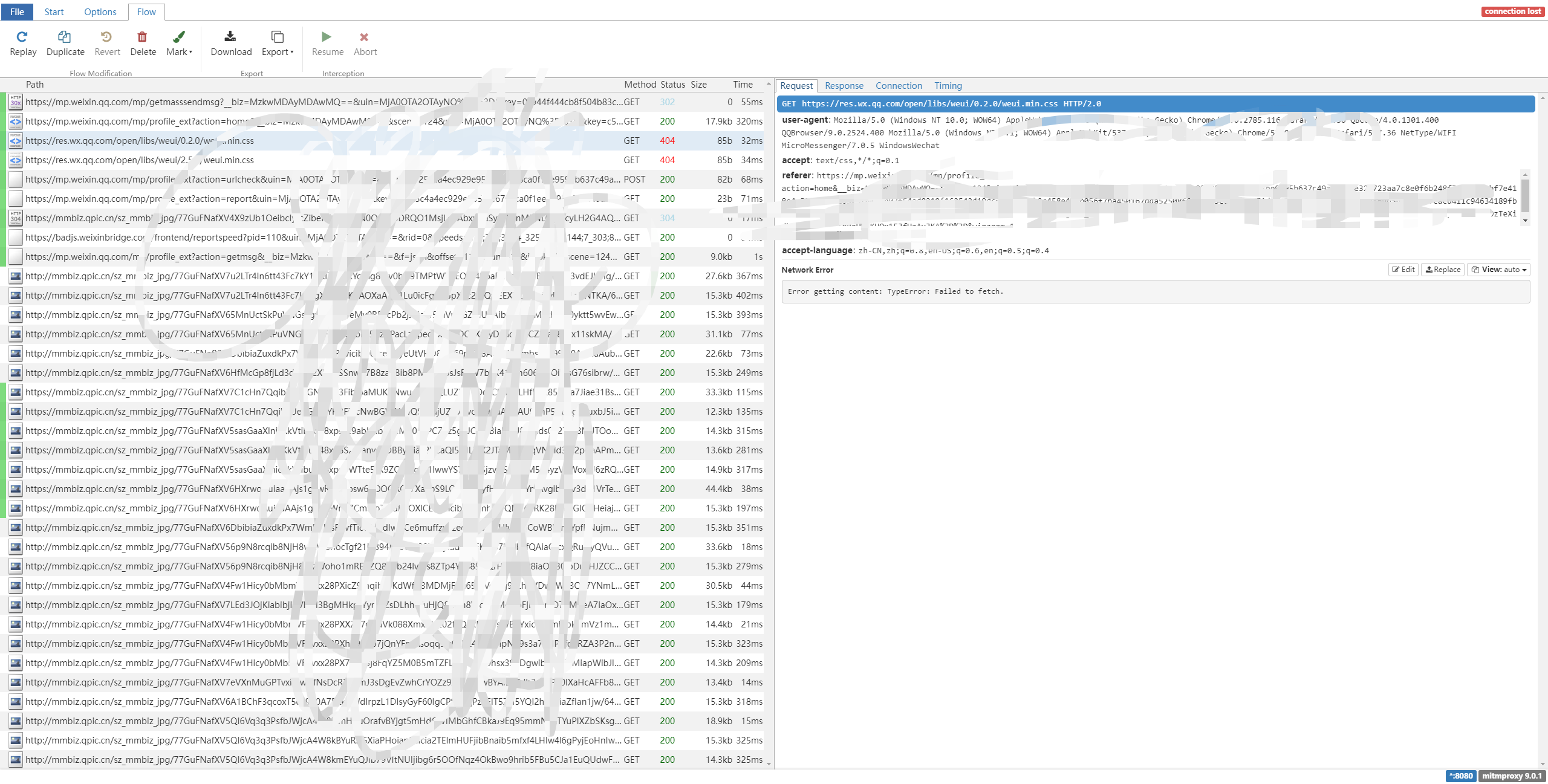
然后我们可以写一个python脚本,用来拦截数据,这里给出示例:
1 | import urllib |
简单加工就可以将数据获取出来了。
如果需要使用代理的话,可以用下方的命令
1 | mitmdump --mode upstream:http://127.0.0.1:7890 -s youtube.py |
ps: 如果想要从python中启动而非使用命令行,请安装mitmproxy7.0.0之前的版本
You can put your
Addonclass intoyour_script.pyand then runmitmdump -s your_script.py. mitmdump comes without the console interface and can run in the background.We (mitmproxy devs) officially don’t support manual instantiation from Python anymore because that creates a massive amount of support burden for us. If you have some Python experience you can probably find your way around.