1
2
3
4
5
6
| 200
)]}'
[["wrb.fr","MkEWBc","[[\"Wán\",null,null,[[[0,[[[null,1]],[true]]]],1]],[[[null,null,null,null,null,[[\"Play\",null,null,null,[[\"Play\",[4,5]]]]]]],\"en\",1,\"zh-CN\",[\"玩\",\"zh-CN\",\"en\",true]],\"zh-CN\",[\"玩\",null,null,null,null,[[[\"名词\",[[\"play\",null,[\"玩\",\"游戏\",\"戏\",\"戏剧\",\"比赛\",\"剧\"],1,true]],\"en\",\"zh-CN\"],[\"动词\",[[\"play\",null,[\"玩\",\"玩耍\",\"游玩\",\"演\",\"玩儿\",\"玩弄\"],1,true],[\"enjoy\",null,[\"享受\",\"享有\",\"欣赏\",\"享\",\"拥有\",\"玩\"],3,true],[\"toy\",null,[\"玩\",\"玩弄\"],3,true],[\"have fun\",null,[\"玩\",\"玩耍\"],3,true],[\"amuse\",null,[\"游玩\",\"玩耍\",\"娱\",\"玩\",\"敖\",\"惊愕\"],3,true],[\"joke\",null,[\"开玩笑\",\"玩\",\"戏\",\"敖\"],3,true],[\"treat lightly\",null,[\"玩\",\"等闲观之\"],3,true]],\"en\",\"zh-CN\"]],8],null,null,\"zh-CN\",1]]",null,null,null,"generic"],["di",25],["af.httprm",24,"8012391421297243024"]]
Process finished with exit code 0
|








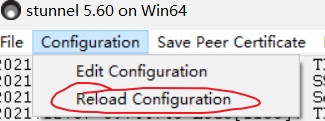
 自己试了一下发现是因为传值格式才会返回400,下面简单讲一下自己的流程
自己试了一下发现是因为传值格式才会返回400,下面简单讲一下自己的流程




